
Introduction
De très nombreuses moissonneuses batteuses sont équipées de capteur de rendement, beaucoup moins ont la capacité de créer des cartes de rendement géo-référencées permettant d’analyser la variabilité intra-parcellaire de la culture.
Le capteur enregistre le flux de récolte dans l’élévateur à grain à intervalles de temps régulier, fonction de la largeur de coupe et de la vitesse de la machine, on peut donc en déduire le rendement instantané. Ce point est enregistré à la position fournie par le capteur GPS et corrigé selon le temps de montée du grain de la zone où il a été coupé à l’endroit du capteur.
La lecture directe de ces cartes de points n’est pas évidente, des algorithmes permettent de traiter ces données afin de rendre l’information plus lisible.
Ces cartes se présentent ainsi:

Matériels et méthodes
Une carte de rendement sur une parcelle de maïs de 17.5 ha a été utilisée, le nombre de points de rendement de la carte est de 30666 soit environ 5.7 m² par point.
Lorsque la machine accélère ou ralentit, le niveau de rendement instantané change avec les inconvénients de lecture que cela implique.
Une carte au format raster serait beaucoup plus pédagogique pour une bonne interprétation de l’hétérogénéité parcellaire du potentiel de la culture.

Deux techniques vont être combinées pour améliorer la lecture de ces cartes: Le kriging et le clustering.
La méthode dite de “kriging” va créer une grille de point dans le contour de la parcelle avec une résolution fonction du niveau de précision requis.
Son objectif est d’éliminer les valeurs abérrantes, par exemple, lorsque la machine s’arrête puis repart, le rendement est à 0 pendant quelques mètres puis très élevé, le krigeage va permettre de lisser ces données.
Les valeurs des points vont être calculées par une fonction d’interpolation d’après les points environnants et de leur distance. C’est la méthode dite de “Poids proportionnels à la Distance Inverse” (Inverse Distance Weighting)
D’après cette nouvelle grille de données rendement de la parcelle on peut les convertir en rendement par unité de surface géo-référencée, on obtient alors un raster, un filtre numérique va être appliqué sur une résolution très fine du raster afin de lisser les données selon une loi de Gauss.
Ensuite un algorithme de classification peut être appliqué sur cette résolution fine et débarrassée du bruit local, l’algorithme que j’utilise reprend la méthode des “kmeans”, avec une particularité en ce sens qu’il détermine seul le nombre de classes afin qu’il soit le plus bas possible sans perdre d’information par rapport à l’image d’origine. On procède itérativement en faisant varier le nombre de classes, et en analysant le coefficient de corrélation entre les données d’origine et les données groupées, le point d’inflexion de la courbe asymptote constitue alors l’optimum cherché, l’abscisse de la courbe est le nombre de classes optimal.
Résultats
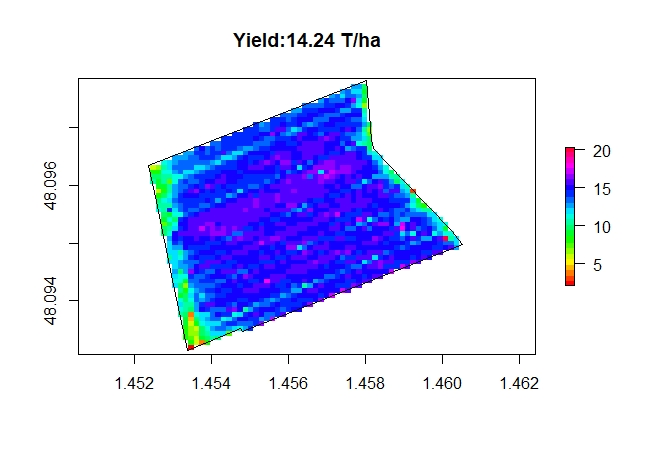
Cette carte issue du krigeage (en français pour kriging) des données brutes sorties machine fait apparaitre une bonne homogénéité de la parcelle mis à part les bordures de champs.
Sur le graphique ci dessus, chaque cellule fait 52 m².
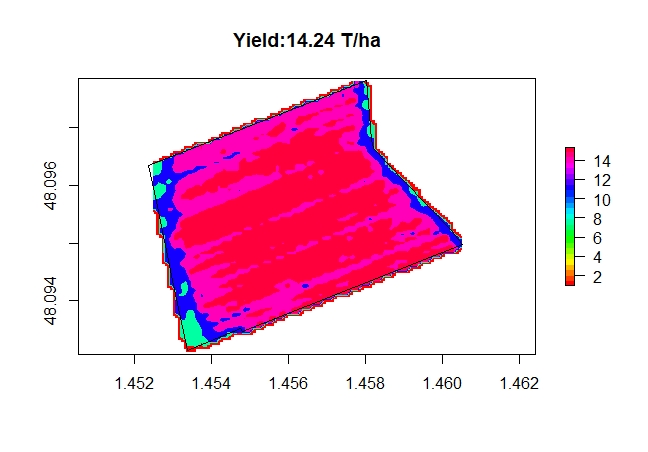
L’algorithme de classification ci dessous montre la faible hétérogénéité de la parcelle.
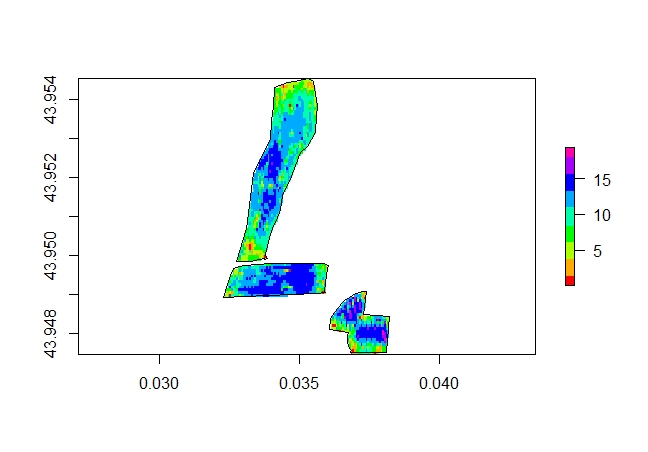
Exemple sur une autre parcelle:

Ensemble de trois parcelles de maïs récolte 2019.

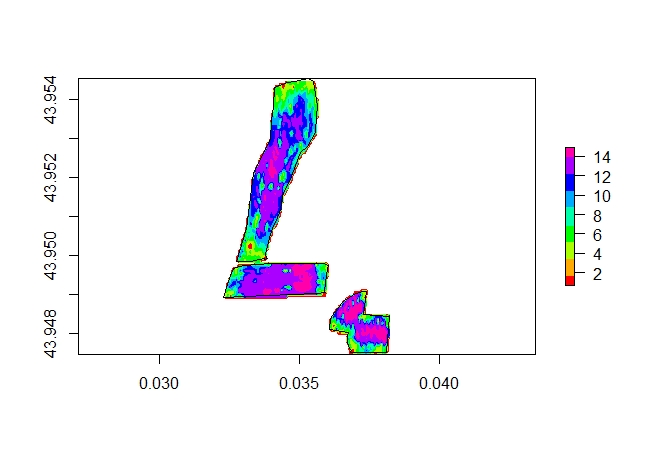
Discussion
Deux axes seront à explorer:
- Variation de la dimension des pixels de la grille d’interpolation lors du krigeage.
- Méthodologie employée par l’algorithme (type de variogramme, nombre de cellules voisine utilisées pour l’interpolation)
L’objectif est évidement que la moyenne de la carte traitée corresponde au rendement de la récolte pesée. C’est une condition indispensable.
Après cette vérification, l’intérêt est de comparer les cartes de rendement issues de la combinaison du modèle et des images satellites afin de produire des coefficients de corrélation entre les cartes de rendement prévues et la carte issue du traitement présenté dans cet article.